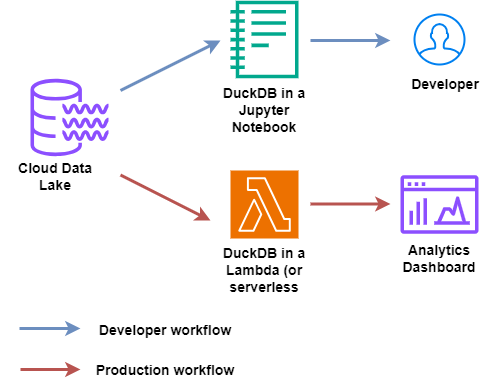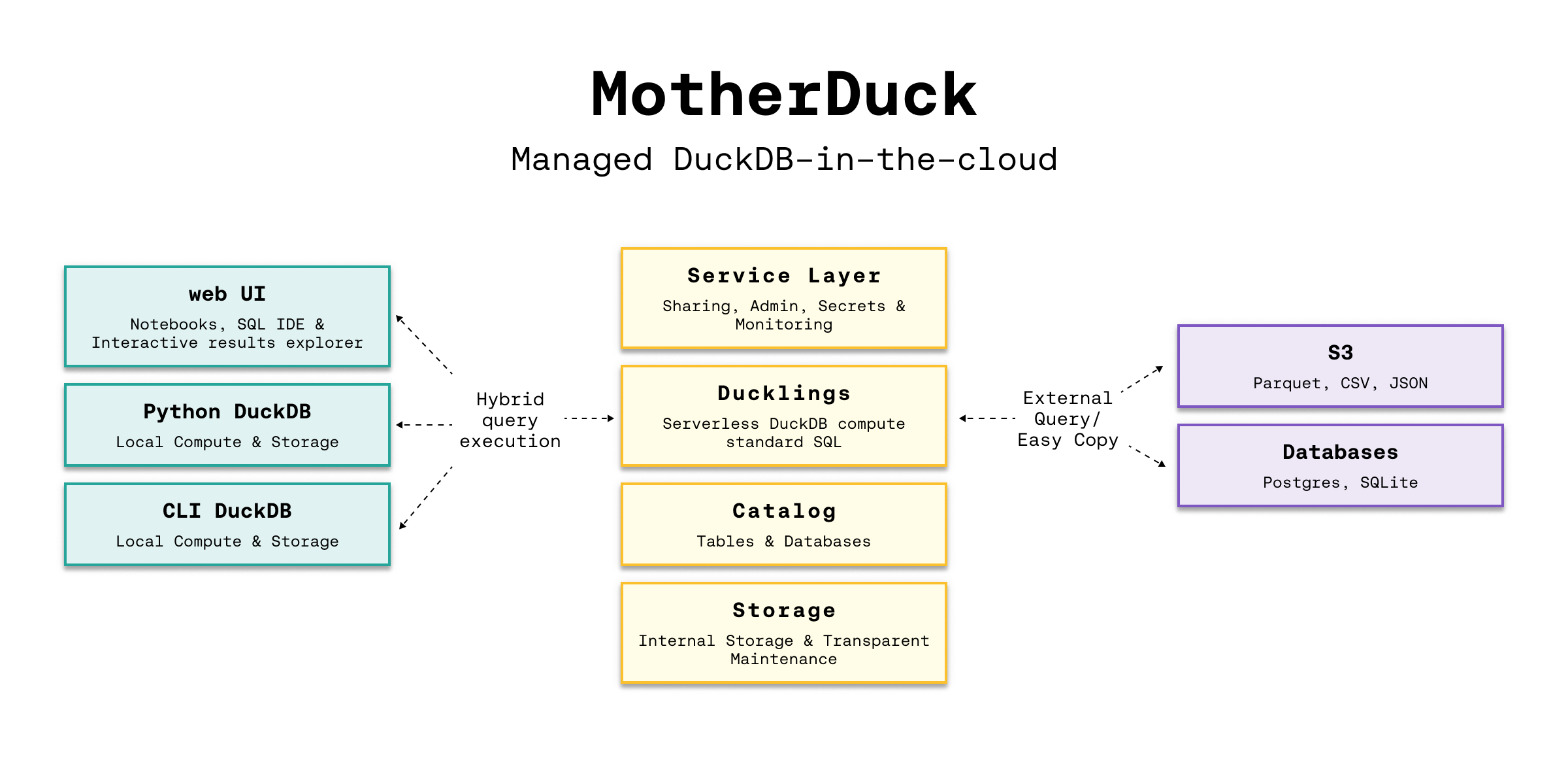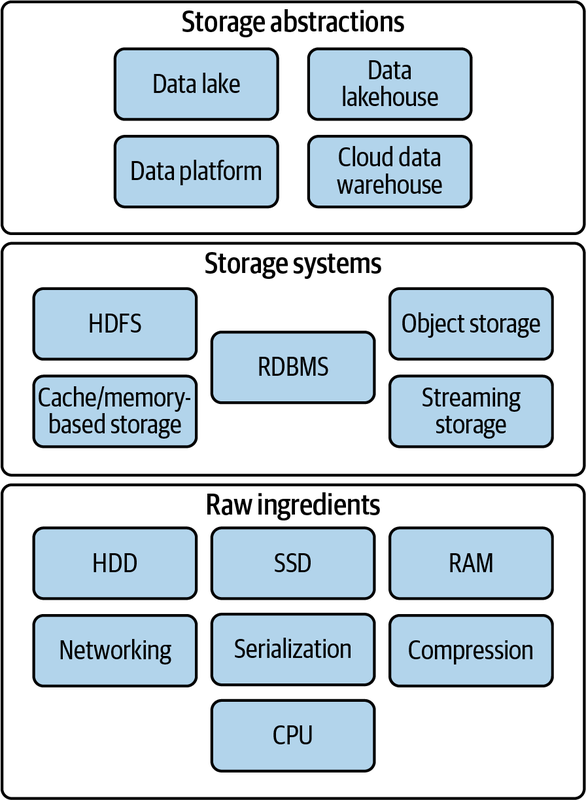






Code
graph TB
Start[Start] --> Read[Read entire CSV<br/>10 GB in memory]
Read --> Filter[Filter rows<br/>Create new DataFrame 6 GB]
Filter --> Select[Select columns<br/>Create new DataFrame 2 GB]
Select --> Group[Group and aggregate<br/>Final result]
Group --> End[End]
Read -.->|Peak Memory| Mem1[10 GB]
Filter -.->|Peak Memory| Mem2[16 GB total]
Select -.->|Peak Memory| Mem3[18 GB total]
style Read fill:#ff6b6b,stroke:#c92a2a,stroke-width:2px,color:#fff
style Filter fill:#ff6b6b,stroke:#c92a2a,stroke-width:2px,color:#fff
style Select fill:#ff6b6b,stroke:#c92a2a,stroke-width:2px,color:#fff
style Group fill:#ffa94d,stroke:#e67700,stroke-width:2px,color:#fffgraph TB
Start[Start] --> Read[Read entire CSV<br/>10 GB in memory]
Read --> Filter[Filter rows<br/>Create new DataFrame 6 GB]
Filter --> Select[Select columns<br/>Create new DataFrame 2 GB]
Select --> Group[Group and aggregate<br/>Final result]
Group --> End[End]
Read -.->|Peak Memory| Mem1[10 GB]
Filter -.->|Peak Memory| Mem2[16 GB total]
Select -.->|Peak Memory| Mem3[18 GB total]
style Read fill:#ff6b6b,stroke:#c92a2a,stroke-width:2px,color:#fff
style Filter fill:#ff6b6b,stroke:#c92a2a,stroke-width:2px,color:#fff
style Select fill:#ff6b6b,stroke:#c92a2a,stroke-width:2px,color:#fff
style Group fill:#ffa94d,stroke:#e67700,stroke-width:2px,color:#fff