Lecture 11
Spark Structured Streaming
Up to now, we’ve worked with batch data
Processing large, already-collected batches of data.
How do we work with streams?
Processing every value from a stream of data — values that are constantly arriving.
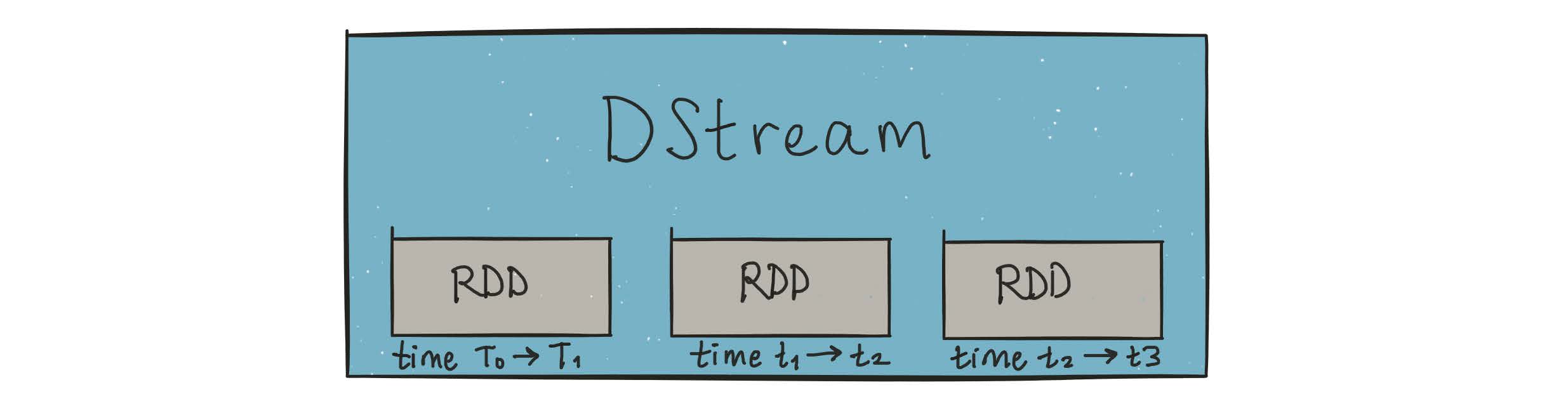
Spark solved this with DStreams — via microbatching
DStreams are represented as a sequence of RDDs.
A StreamingContext is created from an existing SparkContext:
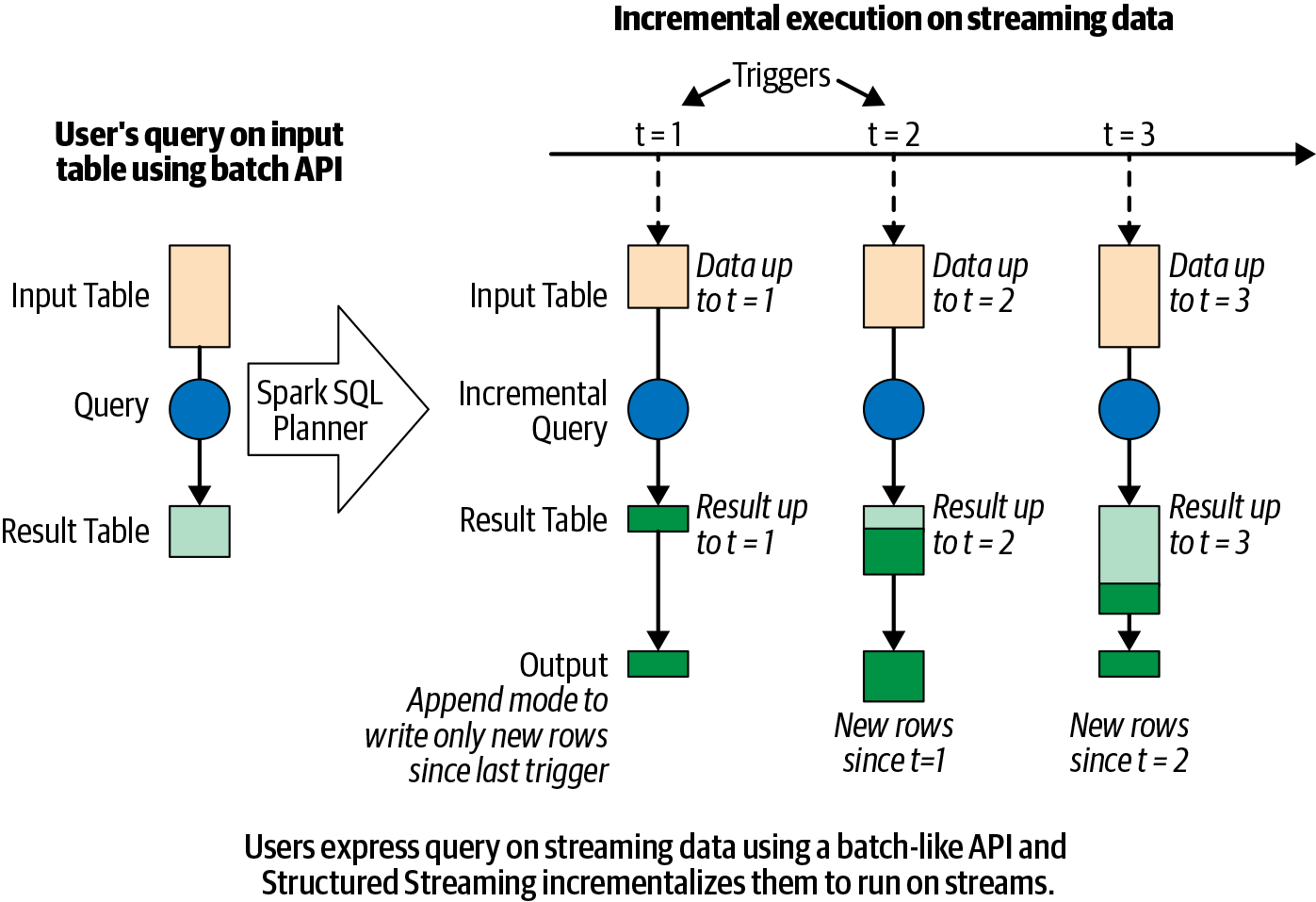
The Programming Model
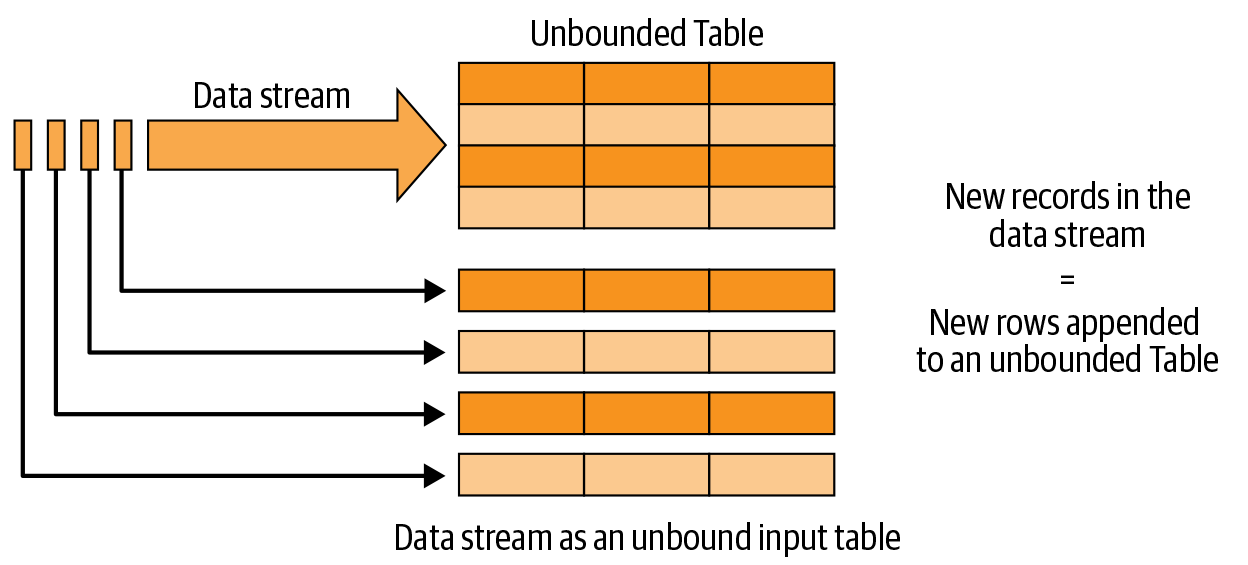
The Programming Model
- Every new record in the data stream is a new row appended to an unbounded input table
- Spark automatically converts the batch-like query to a streaming execution plan (incrementalization)
- Spark figures out what state to maintain to update results as records arrive
- Triggering policies control when results are updated
Spark Streaming under the hood
Spark SQL analyzes and optimizes the logical plan to ensure incremental, efficient execution on streaming data.
Spark SQL starts a background thread that continuously executes a loop.
The loop continues until the query is terminated.
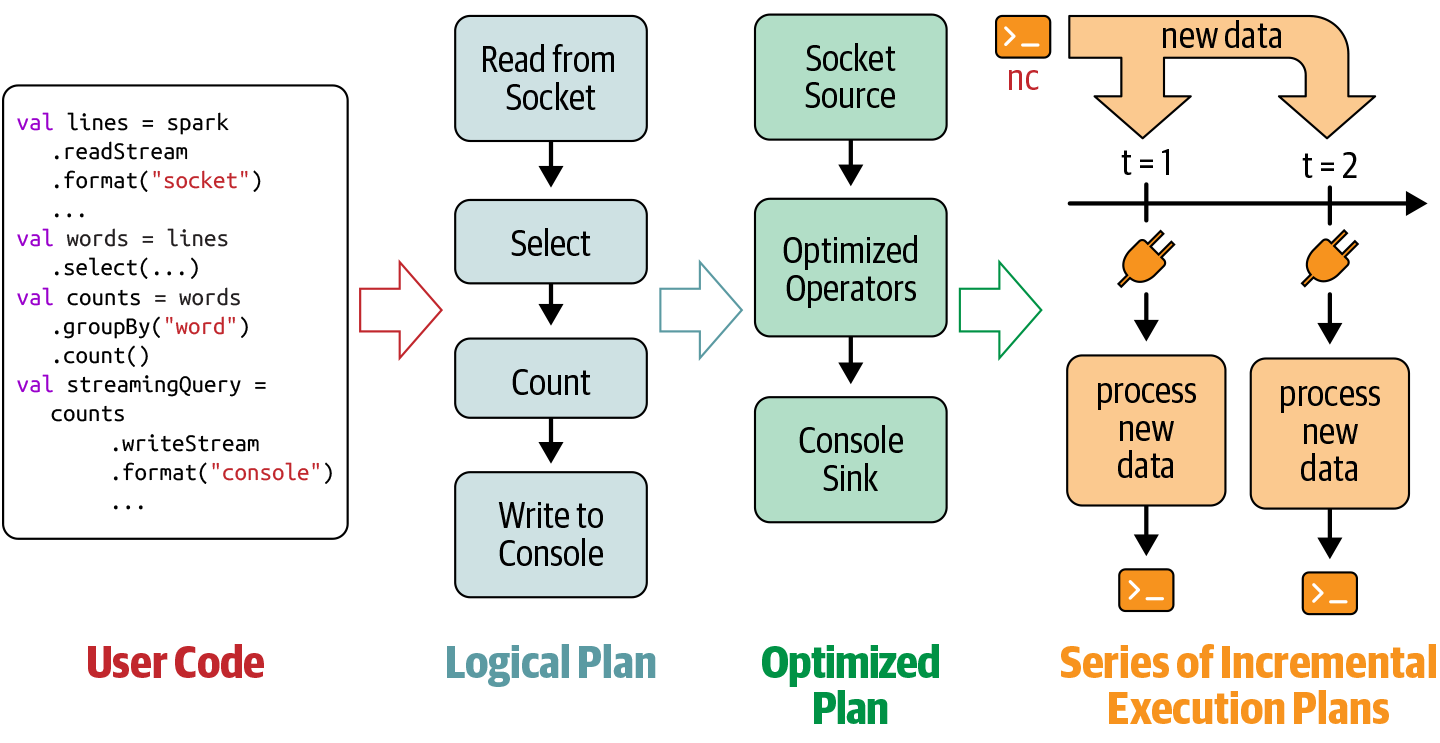
The execution loop
Each iteration:
Based on the configured trigger, the thread checks streaming sources for new data.
New data is executed as a micro-batch — an optimized execution plan reads the data, computes the incremental result, and writes output to the sink.
The exact range of data processed and any associated state are checkpointed to allow deterministic reprocessing on failure.
The loop terminates when…
A failure occurs (processing error or cluster failure) → restart from last checkpoint
The query is explicitly stopped via
streamingQuery.stop()The trigger is set to Once → stops after processing all available data
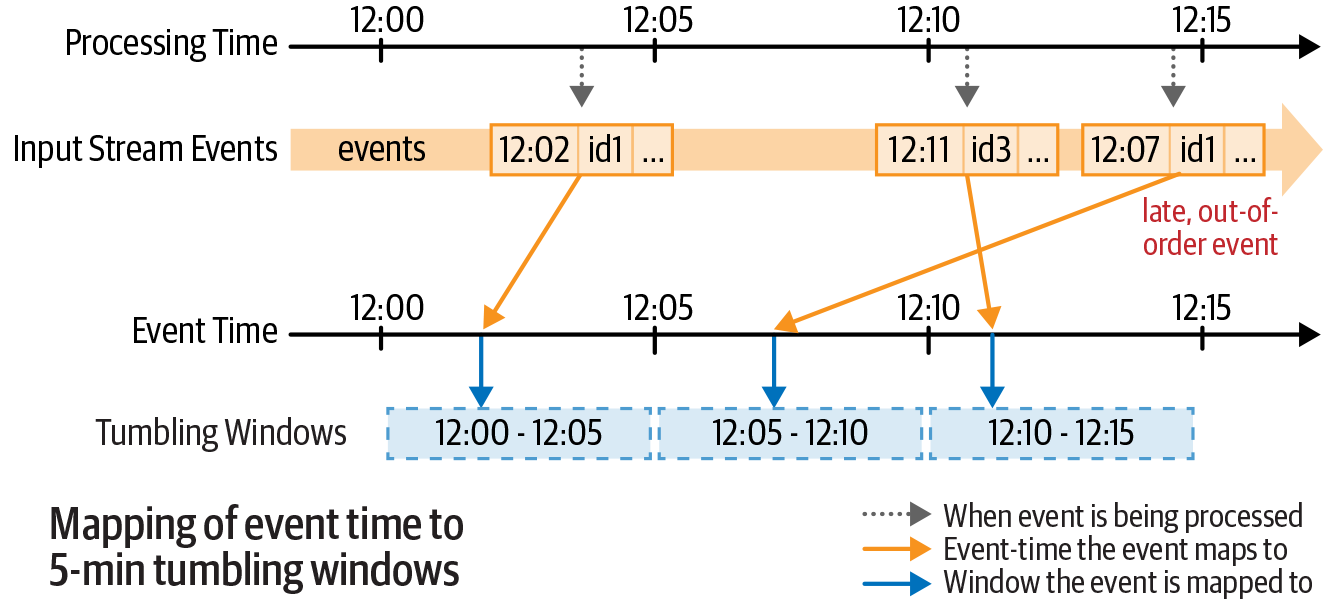
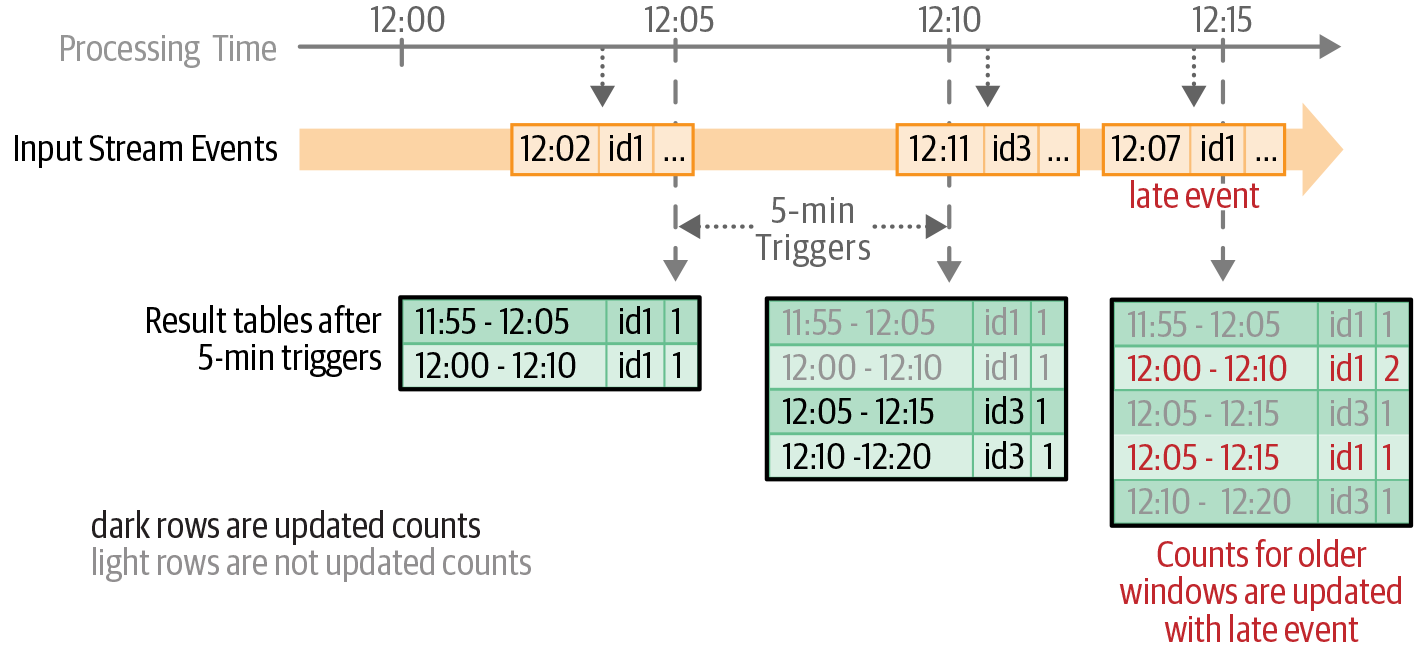
Event-time windows — tumbling
Non-overlapping, fixed-size windows. Each event falls in exactly one window.
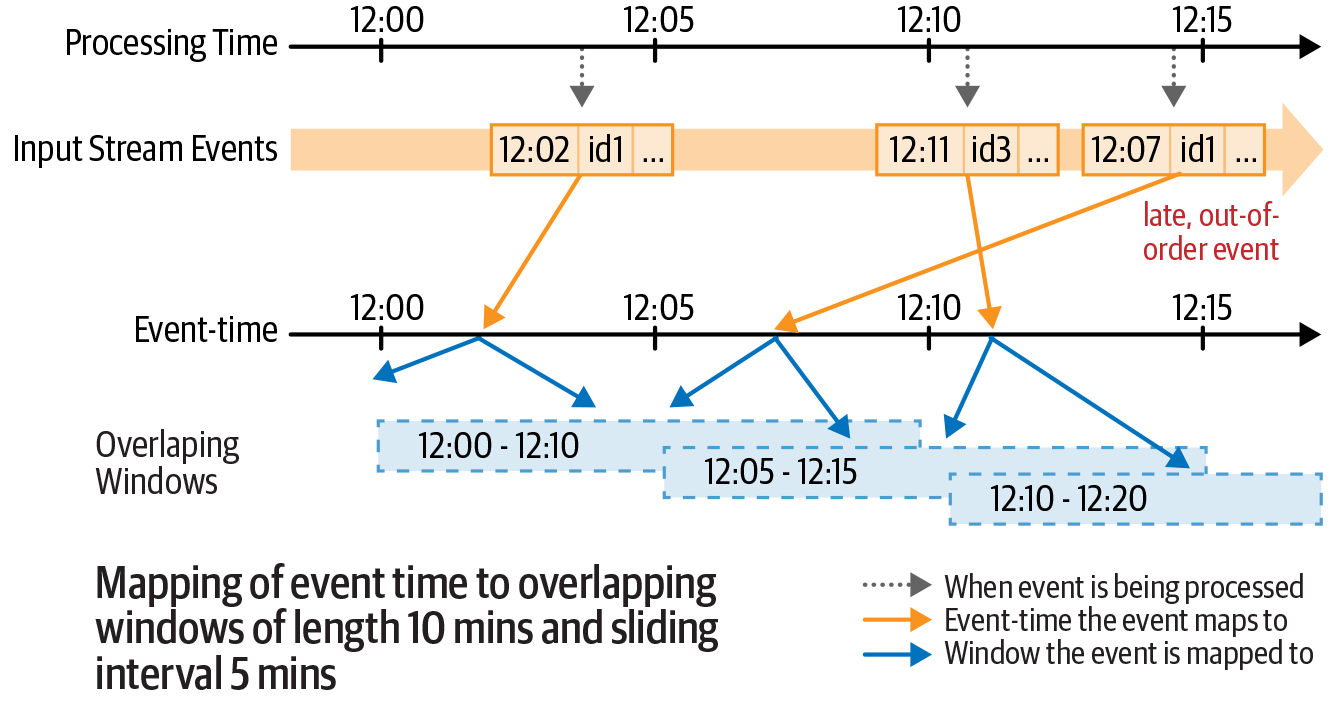
Event-time windows — sliding
Overlapping windows of fixed size and stride. An event can fall in multiple windows.
Updated counts after each trigger
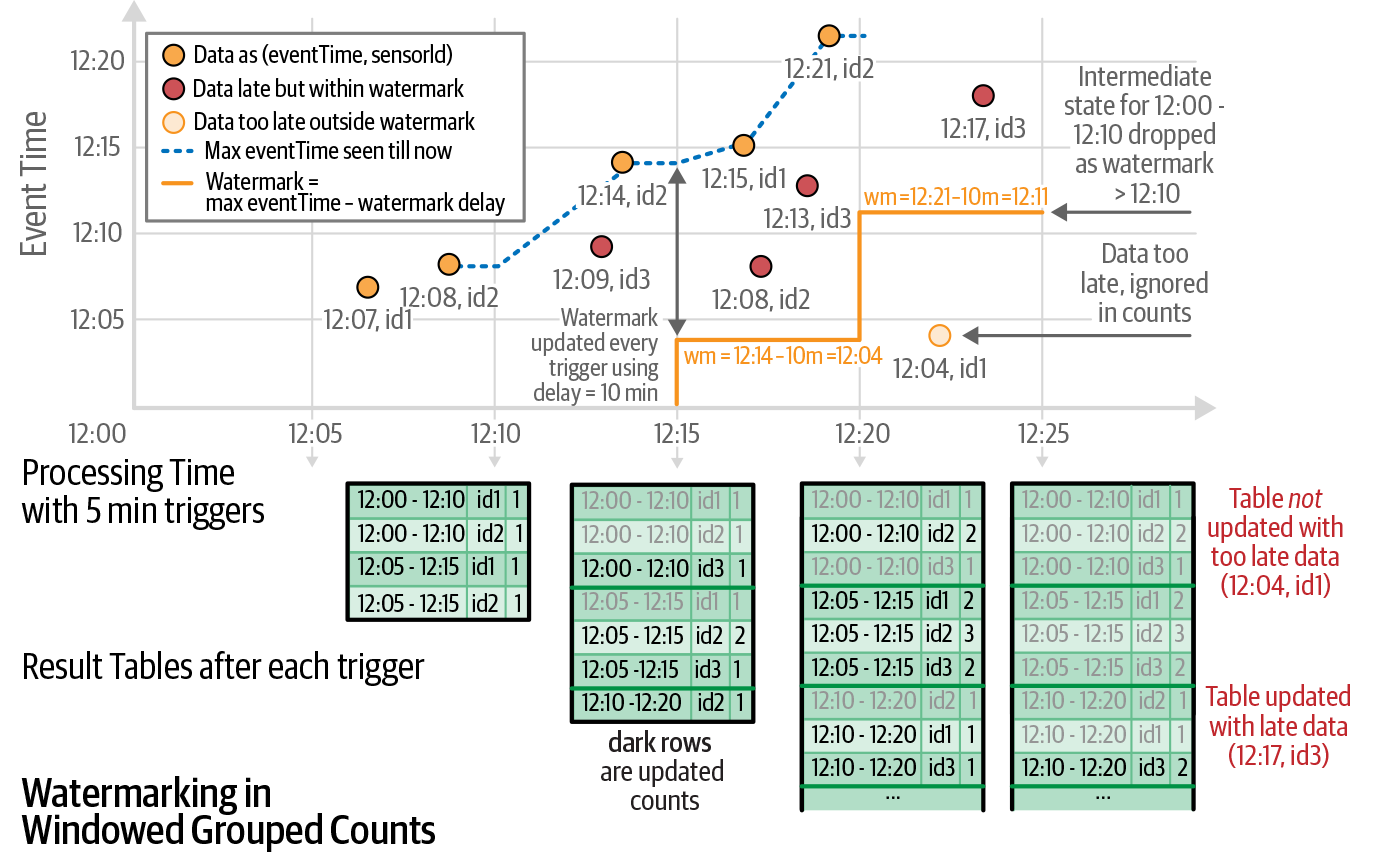
Handling late data — watermarks
Late-arriving data is common in distributed systems (network delays, out-of-order records). A watermark tells Spark how late data can be while still being included.
A watermark is a moving threshold in event time that trails behind the maximum event time seen by the query. The trailing gap — the watermark delay — defines how long the engine waits for late data.
AWS Kinesis

- Similar to Apache Kafka — managed stream ingestion
- Abstracts away configuration and cluster management
- Pricing based on usage (per shard-hour and PUT payload)